feat: add gkd_ascend recipe with NPU support and FSDP backend#102
feat: add gkd_ascend recipe with NPU support and FSDP backend#102vvaen wants to merge 8 commits into
Conversation
This recipe extends the original GKD (On-Policy Knowledge Distillation) recipe with: - Ascend NPU support via HCCL backend and device auto-detection - FSDP/FSDP2 training backend alongside Megatron - Teacher vLLM API backend for connecting to remote serve instances
There was a problem hiding this comment.
Code Review
This pull request introduces an Async On-Policy Knowledge Distillation Trainer adapted for Ascend NPUs, supporting both FSDP/FSDP2 and Megatron backends. It includes a new vLLM API teacher backend and asynchronous schedulers designed to overlap rollout, teacher knowledge acquisition, and actor updates for improved efficiency. Review feedback identifies several issues, such as a missing time import in the vLLM API backend, a leftover debugger call, and redundant imports. Other suggestions include removing debug print statements, correcting inconsistent timeout comments, and hosting documentation images locally to prevent broken links.
| python worker.py --backend vllm_serve --api-base http://localhost:8000 --n-logprobs 256 | ||
| """ | ||
|
|
||
| from concurrent.futures import ThreadPoolExecutor, as_completed |
There was a problem hiding this comment.

The time module is used in _health_check and _call_completions_api but it's not imported. Please add import time at the beginning of the file.
| from concurrent.futures import ThreadPoolExecutor, as_completed | |
| import time | |
| from concurrent.futures import ThreadPoolExecutor, as_completed |
| import ipdb | ||
|
|
||
| ipdb.set_trace() |
There was a problem hiding this comment.

A leftover ipdb debugger call should be removed.
|  | ||
|
|
||
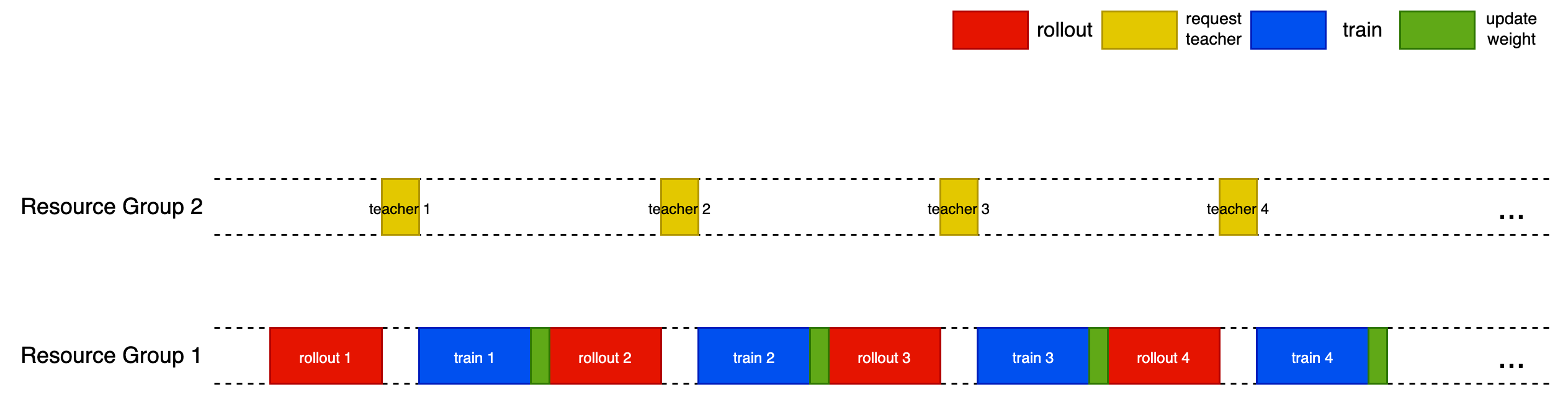
| This recipe supports optional schedulers that overlap generation, teacher querying, and updates to improve throughput without changing the distillation objective. | ||
|
|
||
| #### 4.1.1 One-Step-Off-Policy | ||
|
|
||
|  | ||
|
|
||
| - Warm-up: 2 steps. | ||
| - Overlap pattern: rollout while actor update; weight sync while teacher retrieving. | ||
| - Timing keys: `sync_rollout_weights`, `wait_prev_gen`, `wait_prev_teacher`. | ||
|
|
||
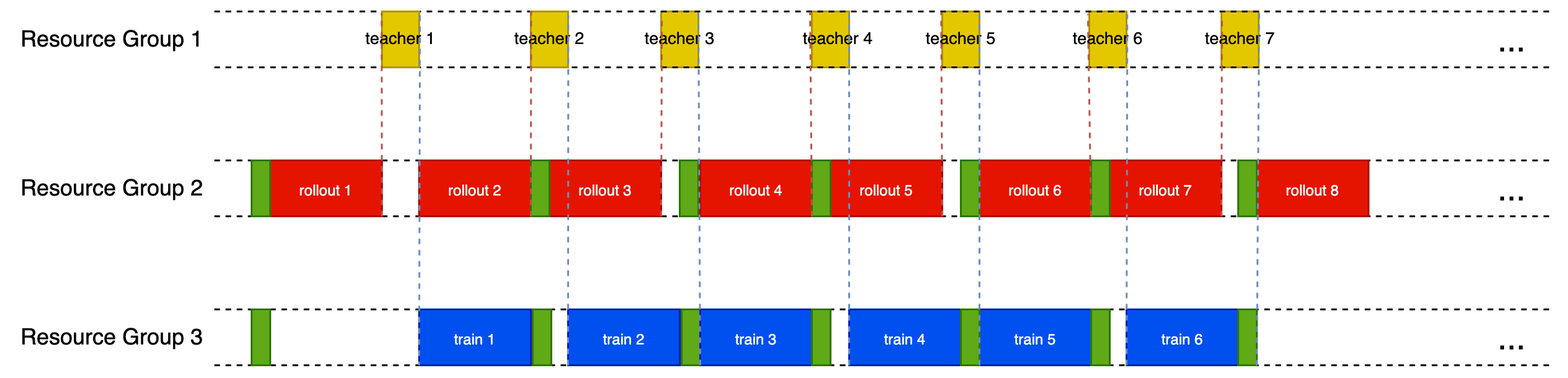
| #### 4.1.2 Two-Step-Off-Policy | ||
|
|
||
| 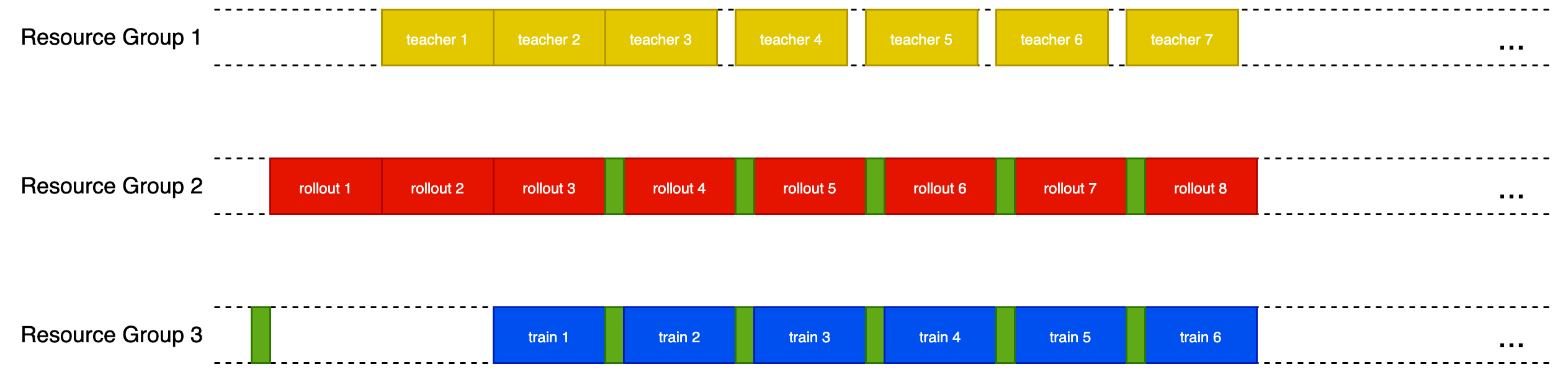 |
There was a problem hiding this comment.

The images for the schedulers are hosted on a personal GitHub fork (eric-haibin-lin/verl-community). To ensure long-term availability and prevent broken links if the fork is removed, it's recommended to move these images into this repository and update the links to point to them locally.
| chunkes = prompts.chunk(len(self.agent_loop_workers)) | ||
| # Use asyncio.gather with ray.get wrapped in asyncio.to_thread to avoid blocking | ||
| import asyncio | ||
|
|
||
| outputs = await asyncio.gather( | ||
| *[ | ||
| asyncio.to_thread(ray.get, worker.generate_sequences.remote(chunk)) | ||
| for worker, chunk in zip(self.agent_loop_workers, chunkes, strict=True) | ||
| ] | ||
| ) |
There was a problem hiding this comment.
There's a typo chunkes which should be chunks. Also, asyncio is imported again inside the method, but it's already imported at the top of the file. This can be cleaned up.
chunks = prompts.chunk(len(self.agent_loop_workers))
# Use asyncio.gather with ray.get wrapped in asyncio.to_thread to avoid blocking
outputs = await asyncio.gather(
*[
asyncio.to_thread(ray.get, worker.generate_sequences.remote(chunk))
for worker, chunk in zip(self.agent_loop_workers, chunks, strict=True)
]
)| (x, y) for x, y in model.state_dict().items() if "_extra_state" not in x and x not in existing_keys | ||
| ] | ||
| for name, param in extra_keys: | ||
| meta_info.append((pp_rank, scan_vpp_idx, idx, name, get_tensor_spec(param))) |
There was a problem hiding this comment.
The variable idx used here is captured from the outer loop (lines 83-85) and will hold the value from the last iteration of that loop for all extra_keys. This is likely not the intended behavior. While idx is not used later, this can be confusing and lead to bugs if the code is modified. It would be clearer to use a distinct value, like a placeholder -1, to indicate that this is not a regular parameter index.
| meta_info.append((pp_rank, scan_vpp_idx, idx, name, get_tensor_spec(param))) | |
| meta_info.append((pp_rank, scan_vpp_idx, -1, name, get_tensor_spec(param))) |
| one_attention_mask = batch.batch["attention_mask"][0].to(torch.bool) | ||
| one_sentence = batch.batch["input_ids"][0] | ||
| print("INFO:", "generate text done.") | ||
| print("DEBUG:", self.tokenizer.decode(one_sentence[one_attention_mask].tolist())) |
There was a problem hiding this comment.
These print statements appear to be for debugging. It's recommended to remove them to avoid cluttering the logs during training.
| socket = self.context.socket(zmq.REQ) | ||
| socket.connect(f"tcp://{self.server_ip}:{self.server_port}") | ||
| socket.setsockopt(zmq.LINGER, 0) | ||
| socket.setsockopt(zmq.RCVTIMEO, 600000) # 接收超时 30 分钟 |
There was a problem hiding this comment.
The comment states the timeout is 30 minutes, but 600000 milliseconds is 10 minutes. Please update the comment to be consistent with the code.
| socket.setsockopt(zmq.RCVTIMEO, 600000) # 接收超时 30 分钟 | |
| socket.setsockopt(zmq.RCVTIMEO, 600000) # 接收超时 10 分钟 |
Summary
This PR adds a new recipe
gkd_ascendthat extends the original GKD (On-Policy Knowledge Distillation) recipe with:Key Changes
main_gkd.pyray_trainer.pydistributed_util.pyfsdp_workers.pyfsdp_kl_loss.pymegatron_workers.pyteacher/vllm_api_backend.pyrun_4b_fsdp.sh/run_4b_megatron.sh