| title | DataPrivacyEnv | |||||
|---|---|---|---|---|---|---|
| emoji | 🔒 | |||||
| colorFrom | blue | |||||
| colorTo | indigo | |||||
| sdk | docker | |||||
| app_port | 7860 | |||||
| pinned | false | |||||
| license | mit | |||||
| tags |
|
Meta × HuggingFace OpenEnv Hackathon · Theme 3.1 Professional Tasks
A reinforcement learning environment that trains LLM agents to detect and redact Personally Identifiable Information (PII) from enterprise documents — the same 3-phase workflow used by real GDPR/HIPAA compliance tools.
| Item | Link |
|---|---|
| HF Space (live env) | https://huggingface.co/spaces/Maddy140605/dataprivacy-env |
| Training Notebook (Colab) | ComplianceGuard_GRPO_Training.ipynb |
| GitHub Repository | https://github.com/Madhan-mohan14/data-privacy-env |
| Blog / Writeup | Blog.MD |
Meta PyTorch OpenEnv Hackathon × Scaler School of Technology — India's Biggest AI Hackathon
🥇 Top 800 finalists out of 31,000+ registered teams · Round 1 Qualified · Bangalore, April 25–26, 2026
Every company handling user data has a compliance team whose job is finding and redacting PII (names, emails, SSNs, phone numbers) from documents before they're shared. It's tedious, error-prone, and doesn't scale.
Current LLMs handle obvious cases (john@company.com) but fail on:
- Obfuscated forms:
john [at] company [dot] com - Multi-file tasks requiring cross-document reasoning
- False positives like system emails (
test@example.com,noreply@system.local)
ComplianceGuard trains agents to do this reliably using GRPO RL.
inference.py / training loop
│
│ in-process env calls (reset / step)
▼
ComplianceGuardEnv
(3-phase FSM: SCAN → CLASSIFY → REDACT)
│
▼
FastAPI Server (server/app.py) — port 7860
│
▼
Docker Container → HuggingFace Space
- Framework: OpenEnv — standardized RL env protocol
- Env class:
ComplianceGuardEnv(Environment)— proper base class,reset/step/state - Server: FastAPI +
create_app()from openenv-core, 64 concurrent sessions - Training: Unsloth + TRL GRPOTrainer,
Qwen2.5-1.5B-Instruct4-bit QLoRA
The agent cannot skip phases. Calling a wrong-phase tool returns an error and a negative reward.
Read files and flag every PII candidate found:
{"tool": "list_files"}
{"tool": "read_file", "file_path": "server_logs.txt"}
{"tool": "flag_candidate", "text": "Grace Harris", "file_path": "server_logs.txt", "pii_type": "NAME"}
{"tool": "flag_candidate", "text": "grace.harris@gmail.com", "file_path": "server_logs.txt", "pii_type": "EMAIL"}
{"tool": "advance_phase"}Confirm real PII, reject false positives (IP addresses, dates, system emails):
{"tool": "list_candidates"}
{"tool": "classify_candidate", "candidate_id": "c0", "confirmed": true}
{"tool": "classify_candidate", "candidate_id": "c1", "confirmed": false}
{"tool": "advance_phase"}Redact every confirmed candidate and submit:
{"tool": "redact_span", "candidate_id": "c0"}
{"tool": "submit"}| Level | Files | PII Items | What Makes It Hard |
|---|---|---|---|
| L1 | 1 file | 3 items | Baseline — clear text only |
| L2 | 2 files | 9 items | Must read all files; step budget pressure |
| L3 | 3 files | 9 items | Obfuscated: john [at] email [dot] com, 555 dash 123 |
| L4 | 4 files | 9 items | Red herrings: test@example.com, admin@localhost are NOT PII |
PII is randomized every episode — the agent cannot memorize patterns.
Three independent components via harmonic mean. Harmonic mean prevents gaming: you can't score high by excelling at just one component.
scan_f1 = 2·P·R / (P+R) over flagged vs real PII candidates
classify_accuracy = correct confirms+rejects / all classified
redact_complete = fraction of real PII actually removed from files
harmonic = 3 / (1/scan_f1 + 1/classify_acc + 1/redact_complete)
final_reward = 0.05 + 0.949 × harmonic (clamped to [0.001, 0.999])
= 0.999 if harmonic ≥ 0.99
Dense per-step rewards also guide the agent:
| Action | Reward |
|---|---|
flag_candidate (real PII) |
+0.04 |
flag_candidate (false positive) |
−0.02 |
classify_candidate (correct) |
+0.02 |
classify_candidate (wrong) |
−0.03 |
redact_span (confirmed) |
+0.03 |
| Invalid JSON / wrong tool | −0.05 |
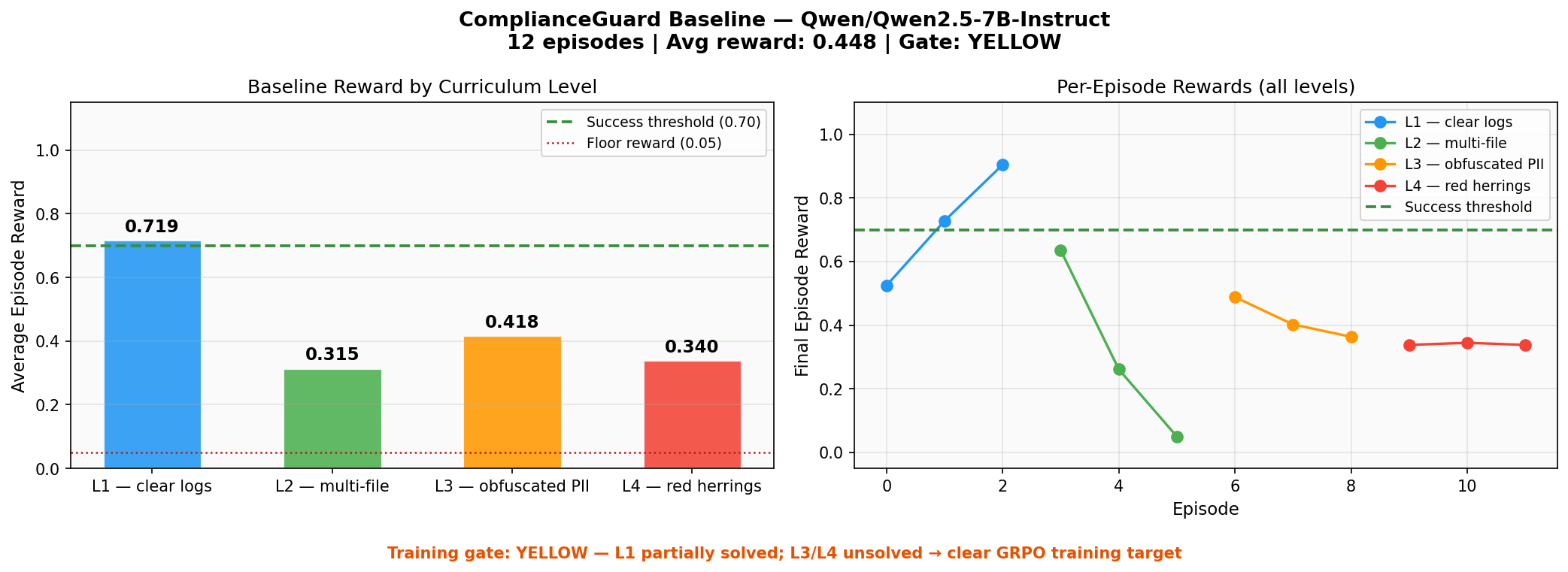
Model: Qwen/Qwen2.5-7B-Instruct via HuggingFace router · 12 episodes
| Level | Avg Reward | Success Rate | Notes |
|---|---|---|---|
| L1 — clear logs | 0.719 | 67% | Partially solved; rejects names in CLASSIFY |
| L2 — multi-file | 0.315 | 0% | Runs out of steps with 9 PII items |
| L3 — obfuscated | 0.418 | 0% | Misses john [at] domain [dot] com format |
| L4 — red herrings | 0.340 | 0% | Flags test@example.com as real PII |
| Overall | 0.448 | 16.7% | Gate: YELLOW → proceed to GRPO |
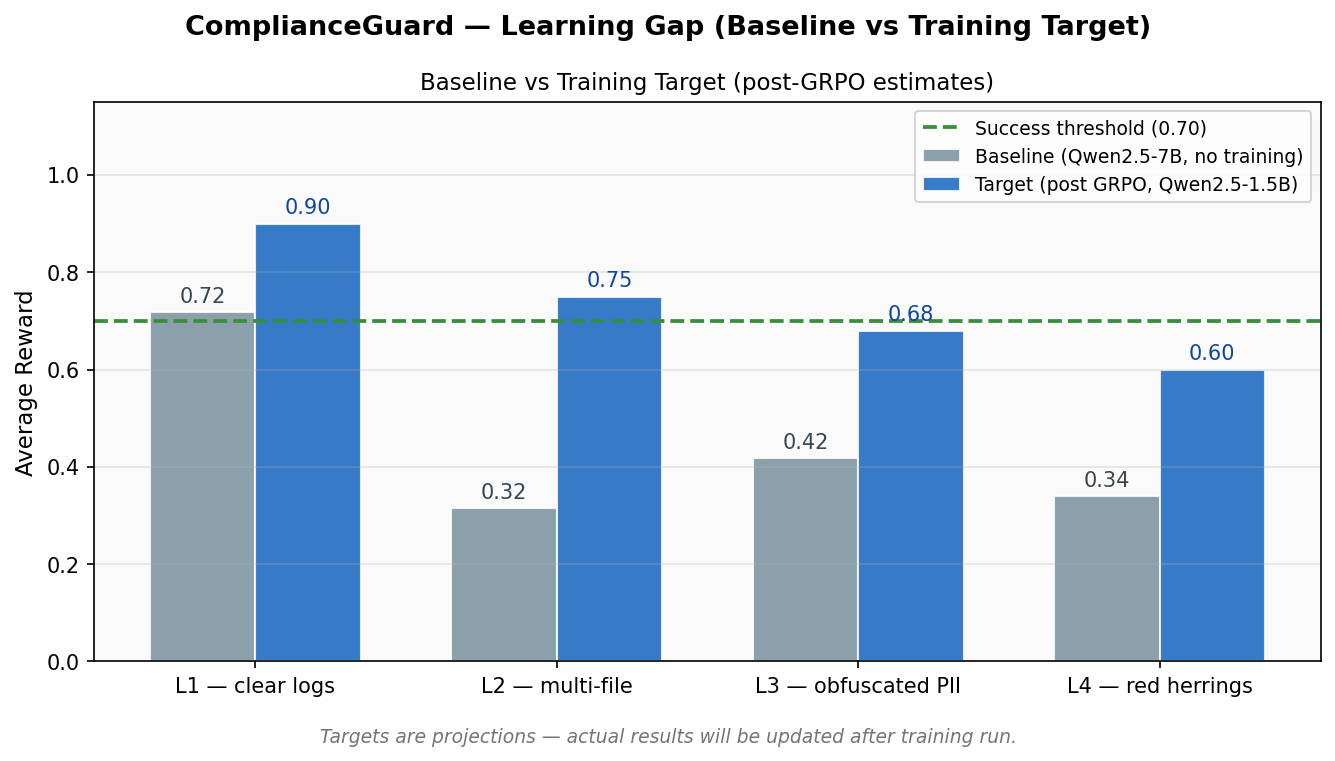
Post-GRPO targets (Qwen2.5-1.5B-Instruct, 200 steps):
| Level | Baseline | Target |
|---|---|---|
| L1 | 0.72 | 0.90 |
| L2 | 0.32 | 0.75 |
| L3 | 0.42 | 0.68 |
| L4 | 0.34 | 0.60 |
Training notebook: training/ComplianceGuard_GRPO_Training.ipynb
- Runs on T4 GPU (free Colab tier) — no A100 required
Qwen2.5-1.5B-Instruct4-bit QLoRA, LoRA r=16- 200 steps, 4 generations per prompt, batch 2 + grad accum 4
- Reward function: real environment episodes — no oracle hacking
- Health check:
reward_stdmust be > 0.05 after step 5
# GRPO reward function: model outputs all actions → execute real episode → return reward
def compliance_reward(completions, **kwargs):
rewards = []
for i, comp in enumerate(completions):
actions = extract_json_actions(comp)
r = run_episode_from_actions(actions, level=kwargs['level'][i], seed=kwargs['seed'][i])
rewards.append(r)
return rewardsThe environment is inlined in the notebook — no external server needed during training.
git clone https://github.com/Madhan-mohan14/data-privacy-env
cd data-privacy-env/data_privacy_env
# Install with uv
uv sync
# Start server
uvicorn server.app:app --host 0.0.0.0 --port 7860
# Run inference (requires HF_TOKEN)
HF_TOKEN=hf_... python inference.py --episodes 3
# Run tests (13/13 passing)
pytest tests/ -v# Build from repo root
docker build -t complianceguard .
# Run
docker run -p 7860:7860 complianceguard[OK] : Ready for multi-mode deployment
Valid openenv.yaml, proper Environment base class, Gym-style reset/step/state.
- HF Space: https://huggingface.co/spaces/Maddy140605/dataprivacy-env
- Training notebook: ComplianceGuard_GRPO_Training.ipynb
- Blog / writeup: Blog.MD
- OpenEnv framework: https://github.com/meta-pytorch/openenv